

Getting Started
Overview
API Endpoint
https://pdfswitch.io/api/
Welcome to PDFSwitch! PDFSwitch provides a simple and robust REST-ful API to integrate HTML to PDF conversion technology into your existing applications and services.
The PDFSwitch API enables the following operations:
- Conversion of raw HTML/URL to PDF documents
- Get result PDF in binary format OR saved in AWS S3 storage
- Customization of your PDF with css, javascript, headers/footers and much more
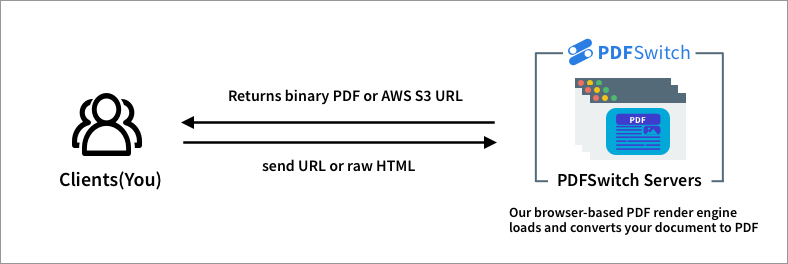
Below is a simple picture of how PDFSwitch works.
We use a browser-based PDF render engine, that makes our result PDFs have high fidelity, just like your originial document. This is different from old PDF render engines out there, which use old, outdated parsing engines which may result in a PDF different from your original document.
Also, to provide our service at reasonable price, we use serverless technology on our backend. For this reason, the first request you are making may be slower than the following subsequent requests, as there is a cold start time, to warm our servers.
If you have further questions or feedback you would like to share with us, always feel free to contact us at support@pdfswitch.io. We would love to hear from you :)
Getting an API Key
PDFSwitch uses API keys to allow access to the API. You can find your API keys on your Dashboad, which you can access by logging in or signing up.
Authentication
PDFSwitch expects the API key to be included in all API requests to the server via HTTP Bearer Auth Scheme. Provide your API key in the Authorization header with the Bearer authentication scheme, with a single space in between the Bearer and YOUR_API_KEY.
Authorization: Bearer YOUR_PDFSWITCH_API_KEY
Conversion API
Convert to PDF
This is the main endpoint of PDFSwitch's API. Simply pass your raw HTML or URL to us and get a PDF in return.
HTTP Request
POST https://pdfswitch.io/api/convert
BODY Parameters
All parameters should be passed as a JSON object. We grouped the parameters into sections by their main usage.
1. Main Options
Default options to manipulate our PDF render engine.
| Parameter | Type | Default | Description |
|---|---|---|---|
| source | string or URL | required | The target document to convert to PDF. Can be an URL or a String of raw HTML. 1. URL Format: The URL of a web page you want to convert. Example: https://example.com2. HTML Format: Raw HTML string that you want to convert. Example: <html><h1>Test</h1></html> |
| page_ranges | string | null | Returns only specified pages of the PDF document. If not provided, it will return all pages by default. Pattern: 1|5-6 |
| page_orientation | string | portrait | Page orientation Enum: portrait|landscapecf) Portrait vs Landscape |
| page_format | string | A4 | Page size for converted pdf Enum: Letter|Legal|Tabloid|Ledger|A0|A1|A2|A3|A4|A5|A6cf) A0~A6 Sizes, Letter~Ledger Sizes |
| page_width | string | null | Custom pdf page width. Use it together with custom page_height. Unit can be one of px|in|mm|cm.Pattern: NUM[px|in|mm|cm]Example: 600px |
| page_height | string | null | Custom pdf page height. Use it together with custom page_width. Unit can be one of px|in|mm|cm.Pattern: NUM[px|in|mm|cm]Example: 600px |
| emulate_media | string | screen | Force CSS media emulation for print or screen. The print option controls how your page looks when printed. Enum: screen|print |
| margins | object | null | CSS style margin sizes. Use it to give space between the limits of the document and captured content.
{"top": "100px", "right": "0px", "bottom": "0px", "left": "300px" }cf) If a certain key [top, right, bottom, left] is not defined, the value for the key is 0px by default. |
| zoom | number | 1 | Allows you to increase the zoom in the document. It should be a float value between 0.1 and 2. Value larger than 1 means zooming in(larger), smaller than 1 means zooming out(smaller). For example, the default 1 means 100% zoom(original state) on the document, 2 means 200% zoom(zoom in), 0.1 means 10% zoom(zoom out) and so on. Example: 1.5 |
2. Injection Options
Options to inject on PDF render.
| Parameter | Type | Default | Description |
|---|---|---|---|
| css | string or URL | null | Additional CSS to be injected into the page before render. Can be an URL or String of CSS Rules. 1. URL: The URL to a file of CSS Rules Example: https://path-to-css-rules2. String: String of CSS Rules. Example: body{background-color: red;} h1{background-color: blue;} |
| javascript | string or URL | null | Additional Javascript to be injected into the page before render. Can be an URL or a String of Javascript code. 1. URL: The URL to a file of Javascript code Example: https://path-to-javascript-code2. String: String of Javascript code. Example: document.getElementById("some-id").style.display = "none" |
| custom_header | string | null | HTML template for custom page header. See Custom Header/Footer section for more details. Example: <header style="font-size:16px;">Page <span class="pageNumber"></span> of <span class="totalPages"></span></header> |
| custom_footer | string | null | HTML template for custom page footer. See Custom Header/Footer section for more details. Example: <footer style="font-size:16px;">Date: <span class="date"></span></footer> |
3. Disable Options
Options to disable on PDF render.
| Parameter | Type | Default | Description |
|---|---|---|---|
| disable_images | boolean | false | Images will be excluded in the rendered PDF. |
| disable_javascript | boolean | false | Will not execute any javascript in the document on render. |
| disable_links | boolean | false | The links(<a><a/> tags) in the rendered PDF will not link to anywhere. |
| disable_backgrounds | boolean | false | The rendered PDF will not have any background images. |
4. Delay Options
Options to delay on PDF render.
| Parameter | Type | Default | Description |
|---|---|---|---|
| delay | integer | 0 | Time in milliseconds to delay render after page load. Max: 10000 |
| wait_for_selector | string | null | CSS selector. Waits until a DOM element matching the provided CSS selector becomes present on the page. Times out after 10 seconds. Example: span.someClassName |
| wait_for_function | string | null | Name of a globally available function(assigned in the window scope). Waits until the function returns a truthy value(boolean true, 1, etc). Times out after 10 seconds.Example: someFunctionName |
5. Request Options
Options on manipulating requests before render.
| Parameter | Type | Default | Description |
|---|---|---|---|
| http_headers | object | null | An object containing additional HTTP headers to be sent on a request before render. All header values must be strings. Example: {"Accept-Language": "en-US,en;q=0.5"} |
6. Storage Options
Options for using 3rd Party Storage(AWS S3) for rendered PDFs.
| Parameter | Type | Default | Description |
|---|---|---|---|
| filename | string | null | If a filename is specified, PDFSwitch will not return a binary PDF but store the PDF in a AWS S3 storage and return the storage URL. See Saving the document to Amazon S3 section for more details. Example: result.pdf |
Custom Header/Footer
Rendered PDFs do not contain any header/footer by default. If you want to add a custom header/footer to your documents, provide an HTML template and PDFSwitch injects it into your document at time of render.
We refer to the html strings you pass as HTML Templates because you can use the below predefined template variables in your html strings. For example, if you want to display the current page number in your PDF pages, you can simply use a placeholder element like <span class="pageNumber"></span>, and our PDF render engine automatically injects the current page number in the pageNumber class element.
Header/Footer Template Classnames
Custom Header/Footer
import requests
response = requests.post(
'https://pdfswitch.io/api/convert',
headers={'Authorization': Bearer YOUR_API_KEY },
json={'source': 'https://www.wikipedia.org/',
# use margins with custom header/footer
'margins': {'top': '50px', 'bottom': '50px'},
'custom_header': '<header style="width:100%;text-align:center;font-size:16px;">Page <span class="pageNumber"></span> of <span class="totalPages"></span></header>',
'custom_footer': '<footer style="width:100%;text-align:center;font-size:16px;">Date: <span class="date"></span></footer>'},
stream=True
)
response.raise_for_status()
with open('result.pdf', 'wb') as output:
for chunck in response.iter_content(chunk_size=1024):
output.write(chunk)
// example in a Node.js env
const request = require('request');
const fs = require('fs');
const options = {
url: 'https://pdfswitch.io/api/convert/',
method: 'POST',
headers: {
'Authorization': 'Bearer YOUR_API_KEY' // Replace it with your API Key
},
body: {
source: 'https://www.wikipedia.org/',
page_orientation: 'portrait'
},
json: true,
encoding: null // this makes the below body a Buffer
};
request.post(options, function (err, response, body) {
if (!err && response.statusCode == 200) {
//do something with PDF Buffer
fs.writeFile('result.pdf', body, function (err) {
if(err) return console.error('writeFile error:', err);
})
} else return console.error('request error:', err);
})
The above command returns a PDF in binary format.
These are the predefined classnames that you can use for dynamic data.
| Classname | Description |
|---|---|
| date | formatted date of render in UTF |
| title | document title |
| url | document location |
| pageNumber | current page number |
| totalPages | total number of pages in the document |
Note that custom header/footer are automatically added to all pages. Also, you must use margins together with custom_header|custom_footer, to provide top and bottom margins to your page so there is space for the custom header/footer to show up.
Examples
We have provided examples of how to perform PDF conversions using our API in various use cases.
Please report problems or request new examples via support@pdfswitch.io.
Saving the document to Amazon S3
import requests
response = requests.post(
'https://pdfswitch.io/api/convert',
headers={'Authorization': Bearer YOUR_API_KEY },
json={
'source': 'https://www.wikipedia.org/',
'filename': 'wiki.pdf'
}
)
response.raise_for_status()
json_response = response.json()
# the filesize unit is MB.
// example in a Node.js env
const request = require('request');
const fs = require('fs');
const options = {
url: 'https://pdfswitch.io/api/convert/',
method: 'POST',
headers: {
'Authorization': 'Bearer YOUR_API_KEY' // Replace it with your API Key
},
body: {
source: 'https://www.wikipedia.org/',
filename: 'wiki.pdf'
},
json: true
};
request.post(options, function (err, response, body) {
if (!err && response.statusCode == 200) {
// do something with S3 URL in json
// the filesize unit is MB.
let json = JSON.parse(body);
console.log(json.url);
} else return console.error('request error:', err);
})
The above command returns JSON structured like this:
{
"url": "https://pdfswitch.s3.us-west-1.amazonaws.com/pdfswitch/d/2/2019-11/46301658ad7e4ace8f97903ac53d88e6/wiki.pdf",
"filesize": 0.797048
}
Amazon Simple Storage Service(Amazon S3) is an object storage service to store data. By passing the filename parameter, PDFSwitch won't return a binary PDF, but upload the PDF to AWS S3 and return an URL to the storage location.
When is this useful?
This feature is useful when you don't want to hold a large binary PDF in memory in your server but to just serve the storage URL to users for download.
Errors
The PDFSwitch API uses the following error codes:
| Error Code | Meaning |
|---|---|
| 400 | Bad Request -- Your request is invalid. |
| 401 | Unauthorized -- Your API key is wrong. |
| 403 | Forbidden -- The resource requested is hidden for administrators only. |
| 404 | Not Found -- The page you tried to reach could not be found. |
| 405 | Method Not Allowed -- You tried to perform an action with an invalid method. |
| 500 | Internal Server Error -- We had a problem with our server. Try again later. |